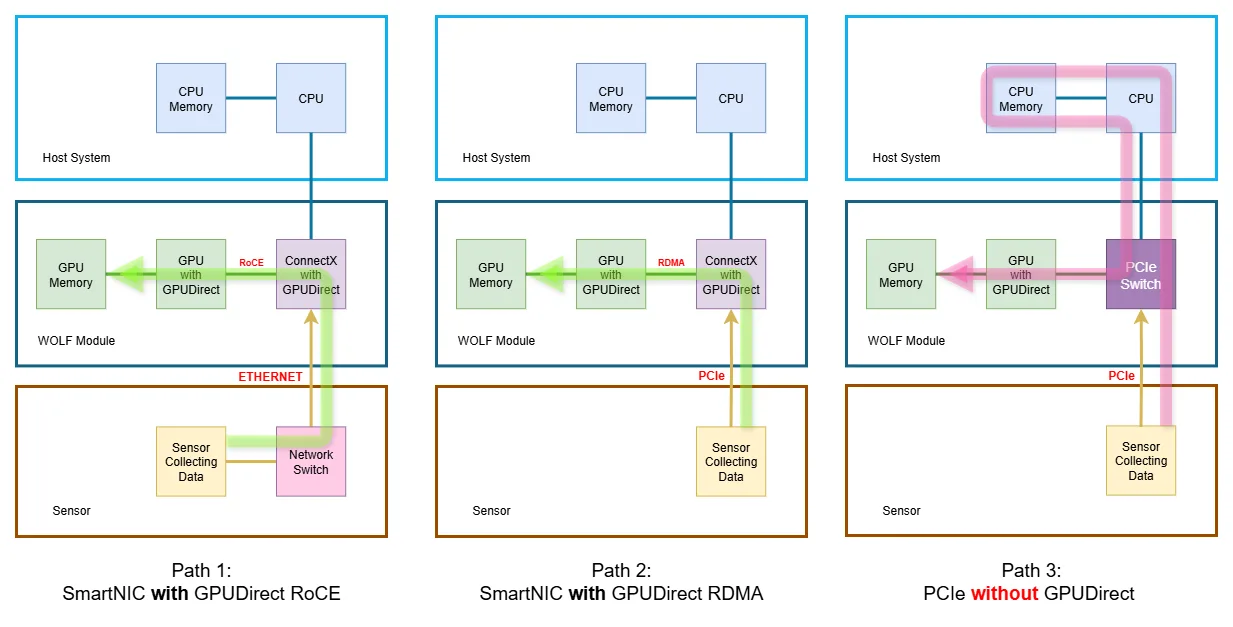
What is GPUDriect RDMA/RoCE
Remote Direct Memory Access (RDMA) lets one PCIe or Ethernet endpoint place data directly into another device’s memory without touching the host CPU. NVIDIA® GPUDirect RDMA exposes pages of GPU VRAM so a compatible SmartNIC like ConnectX can DMA straight into them.
When that RDMA transaction is carried over RoCE (RDMA over Converged Ethernet), you get a zero‑copy data transfer network path with sub‑microsecond latency, that bypasses system DRAM slashing CPU cycles and sustaining line‑rate throughput (maximum bandwidth) —perfect for real‑time sensor‑to‑GPU AI pipelines, edge‑AI inference, video analytics and other rugged embedded‑system workloads.
This paper uses three data‑flow diagrams to compare:
- Optimised Network Path – SmartNIC ➜ GPU via GPUDirect RDMA over RoCE
- Direct‑Attach Path – SmartNIC ➜ GPU via PCIe peer‑to‑peer
- Traditional Copy Path – Sensor ➜ Host DRAM ➜ GPU
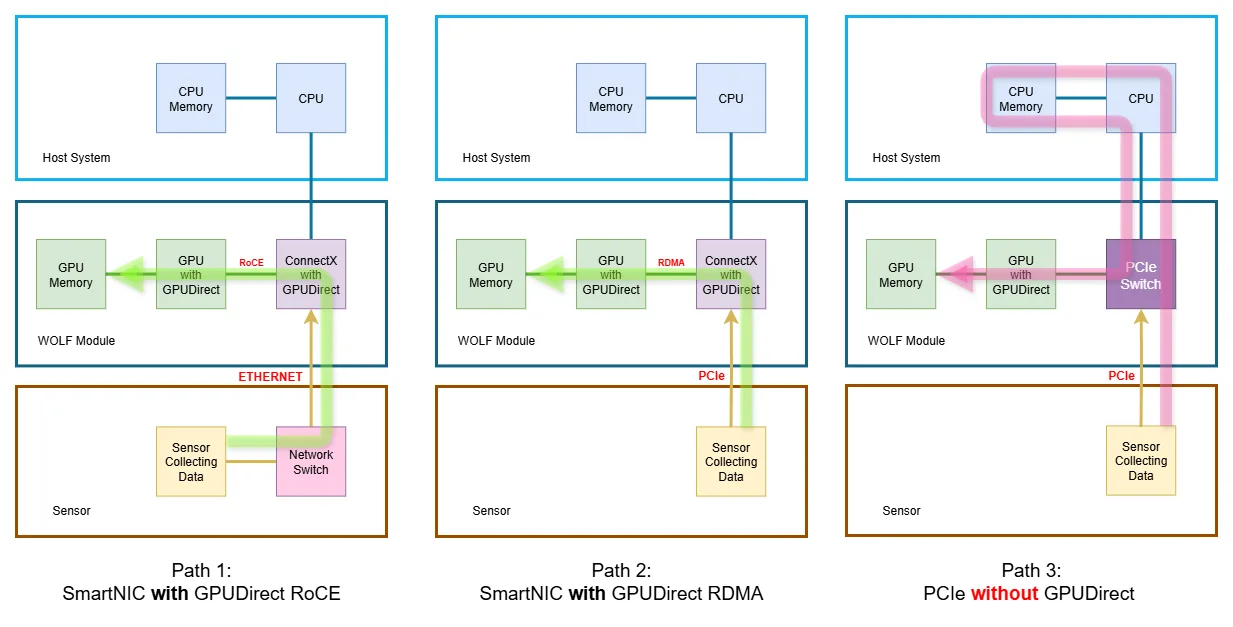
1. Path 1 – SmartNIC with GPUDirect over RoCE (Ethernet) — “Optimized Network Path”
- Flow: Sensor → Network Switch → ConnectX NIC (with GPUDirect RoCE) → GPU Memory
- How it works:
- Sensor packets are wrapped in RoCE frames.
- The ConnectX executes an RDMA WRITE straight into the GPU’s VRAM pages that CUDA has pinned and exposed (BAR1).
- Neither host DRAM nor the CPU’s cache hierarchy ever see the payload.
- Result:
- Ultra-low latency, minimal CPU cycles, one copy (into VRAM)
- Line-rate throughput (maximum bandwidth) limited only by the NIC and PCIe link.
2. Path 2 – SmartNIC with GPUDirect over PCIe (Direct-Attach Path)
- Flow: Sensor (PCIe endpoint) → ConnectX NIC (with GPUDirect RDMA) → GPU Memory
- How it works:
- Sensor data lands in the ConnectX receive FIFO.
- The ConnectX issues an RDMA WRITE, but instead of wrapping it in RoCE/UDP/Ethernet, it emits a single PCIe Memory-Write TLP that targets the GPU’s VRAM.
- Neither host DRAM nor the CPU’s cache hierarchy ever see the payload; the PCIe switch forwards it peer-to-peer from the ConnectX directly into GPU memory
- Result:
- Same CPU bypass and zero-copy benefit as Path 1, but the wire protocol is raw PCIe instead of RoCE.
- Eliminates external Ethernet cabling and the network switch; ideal when the sensor can expose a PCIe interface.
3. Path 3 – PCIe Sensor without GPUDirect (Traditional Copy Path)
- Flow: Sensor (PCIe endpoint) → PCIe Switch → CPU Memory → GPU
- How it works:
- Sensor DMA lands in host DRAM under the root complex.
- The GPU driver (or CUDA runtime) issues a cudaMemcpy / staged DMA to copy that buffer into GPU VRAM.
- Data crosses the PCIe fabric twice
- Result:
- Higher latency (2–3 µs extra), CPU utilization, and memory-bus traffic.
- Throughput capped by CPU and DRAM bandwidth; jitter increases under load.
Quick Benefit Snapshot for WOLF Modules
| Feature | GPUDirect Paths (1 & 2) | No GPUDirect (3) |
|---|---|---|
| Latency | Ultra-low (sub µs) | High |
| CPU Load | Minimal | Heavy |
| Memory Traffic | Direct to GPU | Through host RAM |
| Overall Efficiency | Optimized | Bottlenecked |
The side‑by‑side analysis quantifies how the GPUDirect paths (1 & 2) cut latency, CPU load and memory traffic versus the legacy host‑copy method (3).
In short: if both NIC and GPU advertise GPUDirect/RoCE support, enabling it is the fastest, lowest‑power way to move sensor data onto the GPU—an especially valuable win for the SWaP‑constrained, WOLF modules and other embedded AI systems.